Tomo (2025)
Timeline
This was a screenshot of the absolute first build of the project. At the time it was called "Atmos" because the idea was that it would exist in the atmosphere of the OS rather than always in the foreground.
The app's concept has largely remained the same since the beginning: a lightweight window you can summon as needed for quick LLM chat/inference.
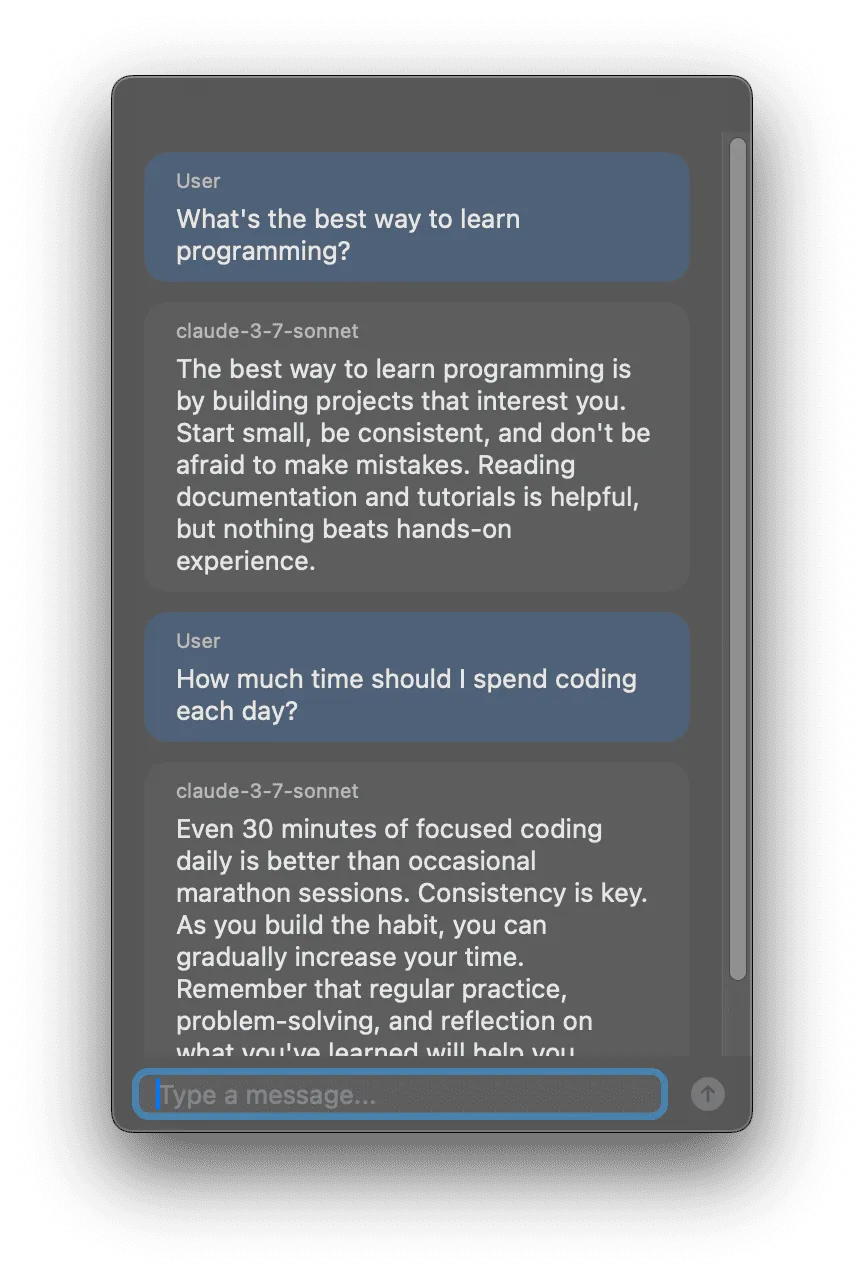
Early development was pretty fast and furious. Within the first day, I had an MVP working, primarily building with Cursor and Claude 3.7 Sonnet. While the UI lacked polish, the core design concept has endured.
You'll notice faded colors in the screenshot because early on I made the window partially transparent. I've since moved away from that though I preserved the feature in the UI settings.
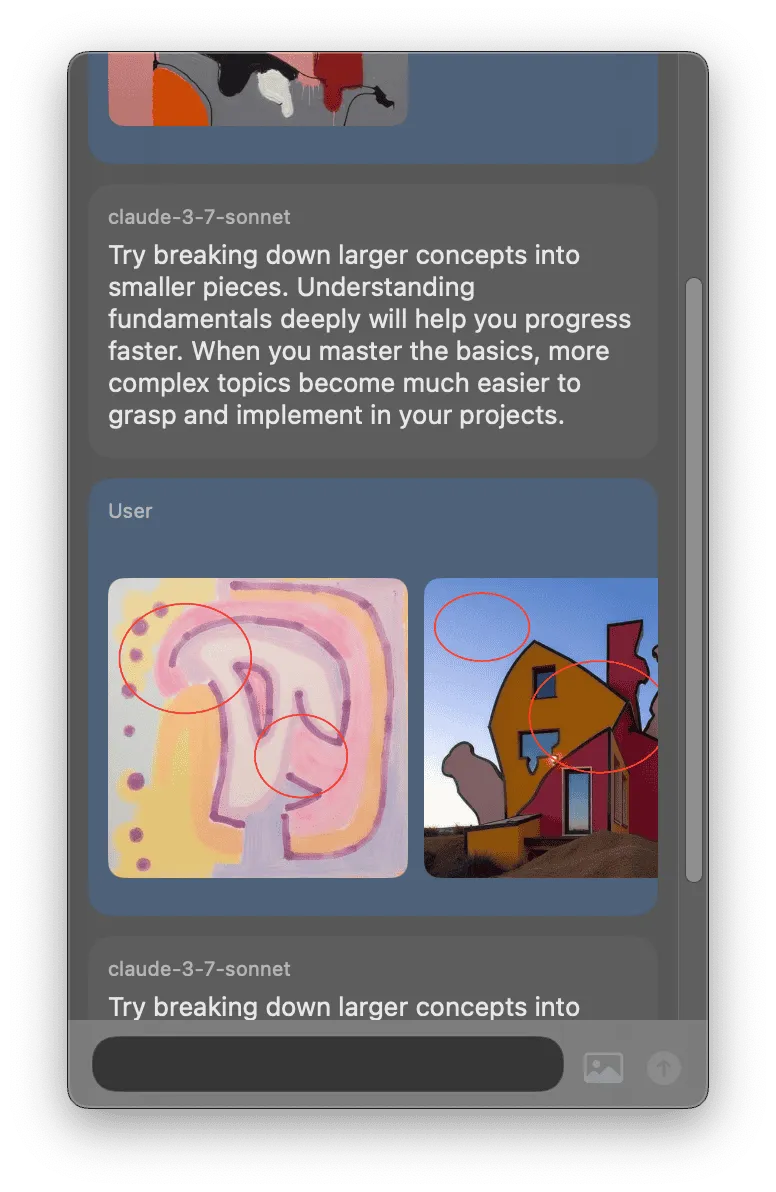
I initially had a vision that when a screenshot was captured with a hotkey, edit controls would appear that would allow you to annotate and crop the screenshot. I spent a full session working on this concept, but it never felt right. The red circles on the images are additions to the images from that feature.
I abandoned it for capturing either a window, screen, or area of the screen.
You'll notice the assistant response is always the same. I had not yet wired up the actual LLM inference API.
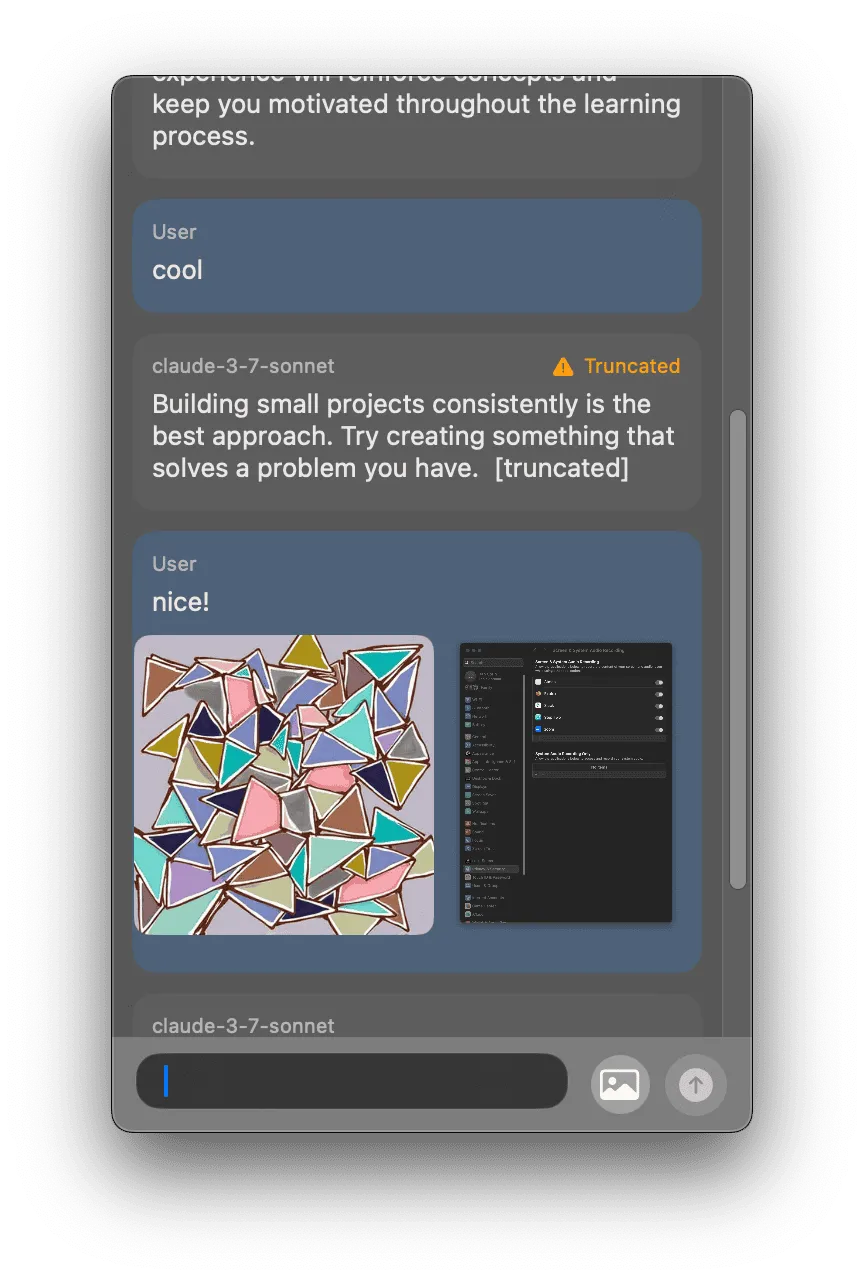
After settling on just attaching images without modifying them, I kept iterating and chiseling away at the interface, trying to coax the idea to life.
Here, I find my nascent design sense pretty striking. I had yet to figure out how to make the spacing of the elements feel good. It almost seemed a bit cartoonish.
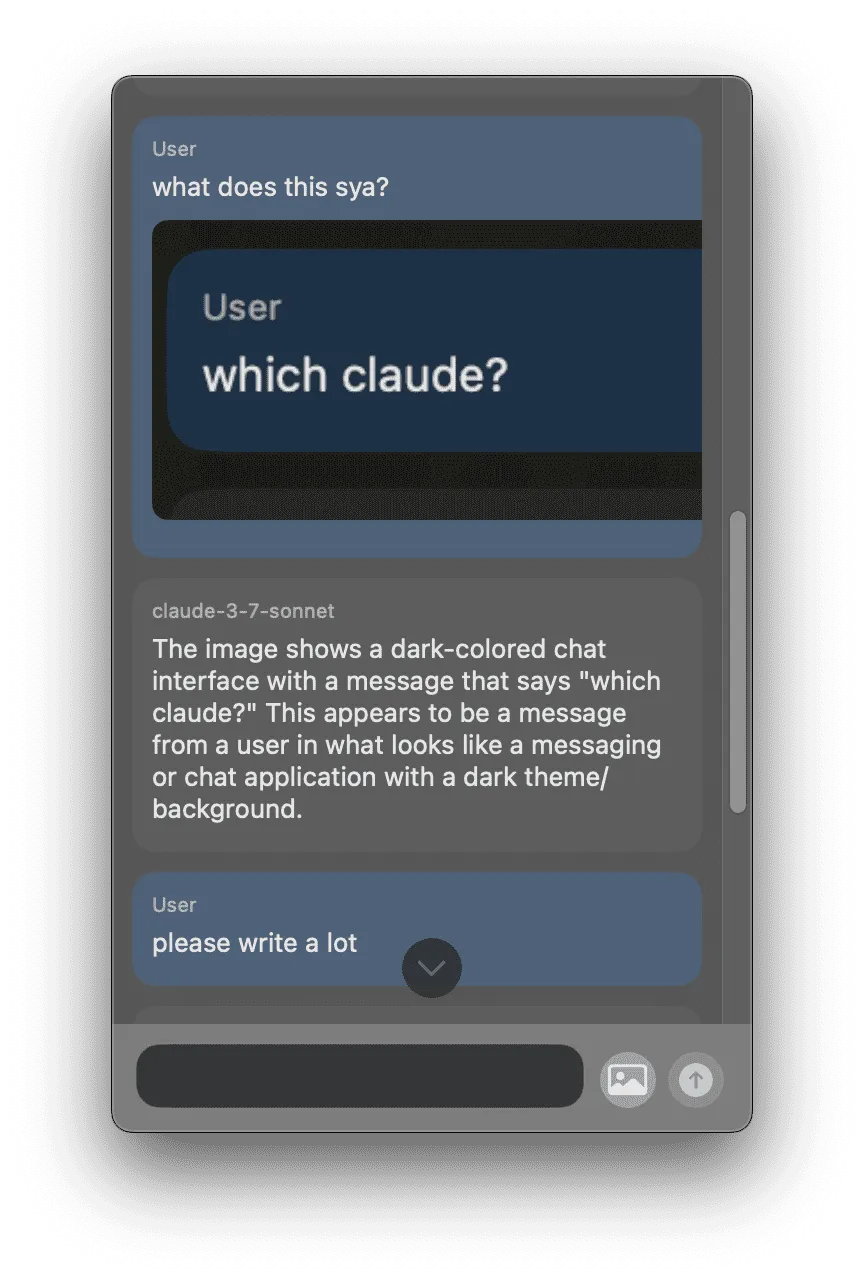
Around the one week mark, I finally had the UX at a point where I was ready to start making calls to an actual LLM. I had held off on implementing this for a relatively long time.
I didn't want to waste time or tokens running inference earlier when the UX didn't work at all. I had already done hours of experimentation with different scrolling approaches.
Initially, I had wanted to autoscroll as the content streamed from the API, but if the user scrolled away, the autoscroll would stop. If the user scrolled back to the bottom while the content was still streaming, the autoscroll would start again. This approach proved tough to implement, but when I finally got it working, I didn't like it at all.
This screenshot shows the streamed response from a multi-modal chat message sent to claude-3-7-sonnet.
The image in the message is a picture of the app itself.
Those colors were what I was seeing on my machine - not the washed out, faded ones which came from taking window screenshots of the app with transparency.
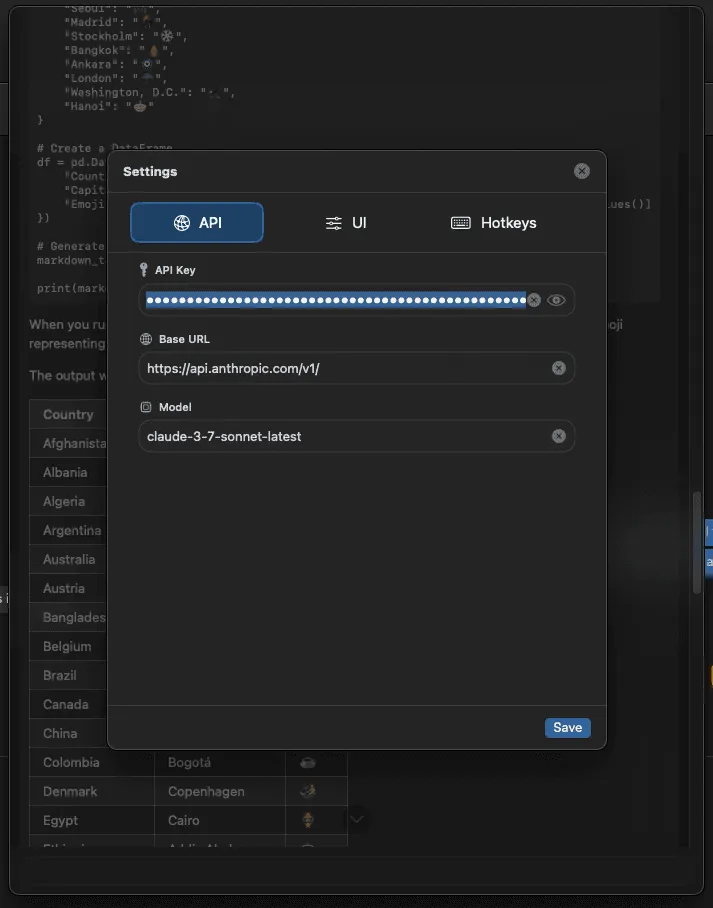
With the core UX in place, I was ready to add configuration to allow the user to choose different models. As a simple chat app, I imagined the user might choose from a few different models depending on the task.
These tasks could include simple things most models can do like
- extract the text from this image
- translate this text to Spanish
- summarize this article
to more complex tasks like writing SQL queries to paste into a query tool or writing Python code to run in Jupyter running in the browser on a remote server.
To easily support model selection, I decided to support any model exposed using the OpenAI Chat Completion API, an unofficial standard that many providers have adopted to lower the switching cost for a developer to try their model using existing code (e.g. Openrouter, Anthropic, Deepseek)
This API supports text and images which is all that is required for the functionality of the app.
In the background, you can notice support for rendering the assistant's response as markdown.
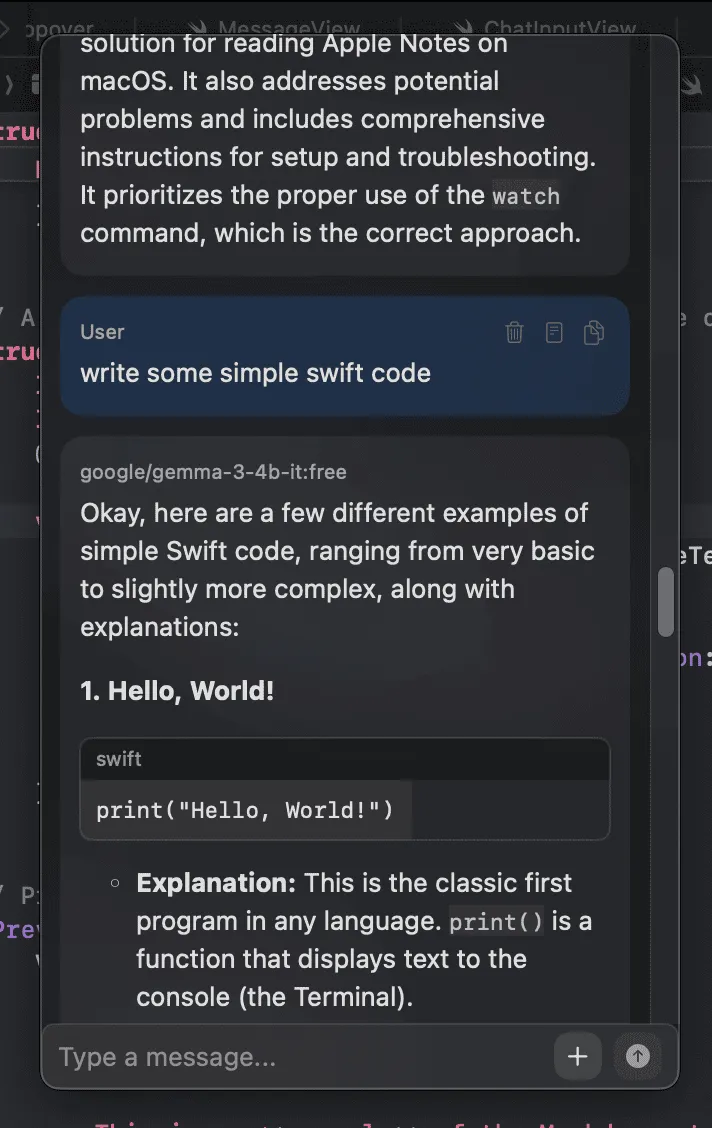
With a first pass of markdown rendering working, I continued to polish the UI and get code blocks working in the markdown rendering.
Compared to the UI today, the input message box still didn't have the padding I eventually added, the width of the contents of the codeblock needed to be fixed, and the scrollbar was still always visible.
A lot of parts were in place at this point. If you've used Tomo, this probably looks pretty familiar (it was still called Atmos at this point).
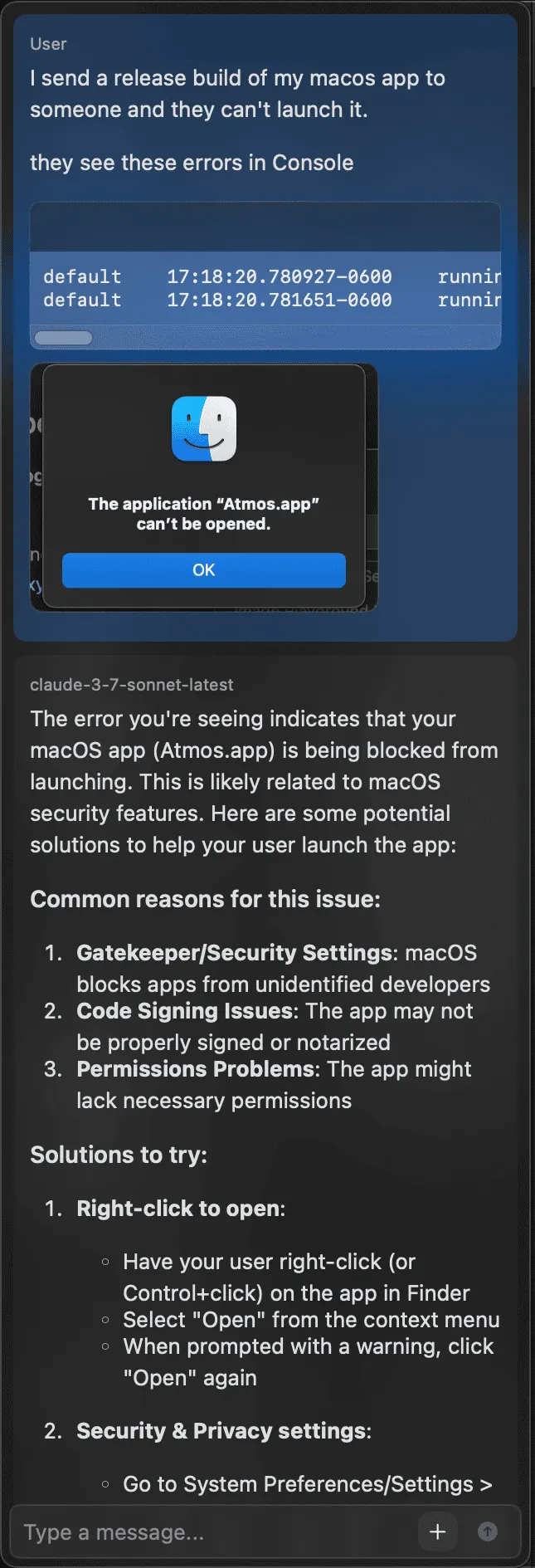
Things were starting to come together and I was pushing to get a build out to share with friends. Having never published an app before, I was unfamiliar with the Apple Developer Program and the process of getting an app notarized so it wouldn't automatically be quarantined.
I used Tomo to learn about the errors I was running into and eventually navigate the process of getting an account setup and the app notarized in Xcode. So much of this process was me sending screenshots to an LLM in Tomo and saying "what now?". It felt like it carried me through a lot of the process.

With the app built and running independently of Xcode, it became a daily driver for my use of LLMs for everything except for coding. Here, I'm using the app to get an explanation of Lilian Weng's article on LLM thinking.
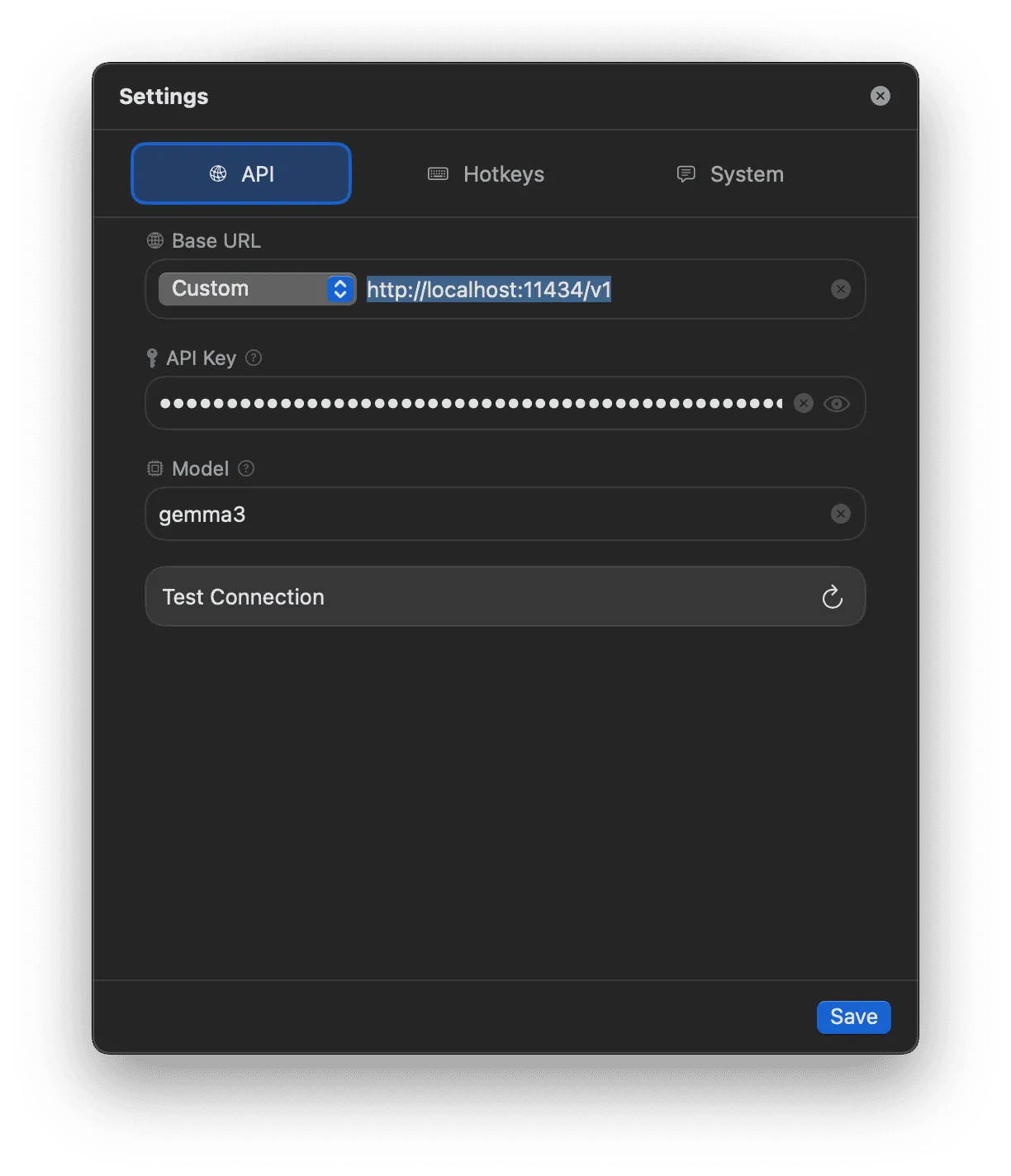
My simple configuration UI required the user to have a reasonably good understanding of the OpenAI API and knowledge of the different provider URLs for using it. I baked some of that knowledge into the app, adding an early version of a provider selector. I kept an option for a custom provider so URLs I didn't add myself could still be easily supported. I also added a "test connection" button which sent an API request to the configured provider and validated the URL and API key were working. This saved me a bunch of time and frustration when testing.
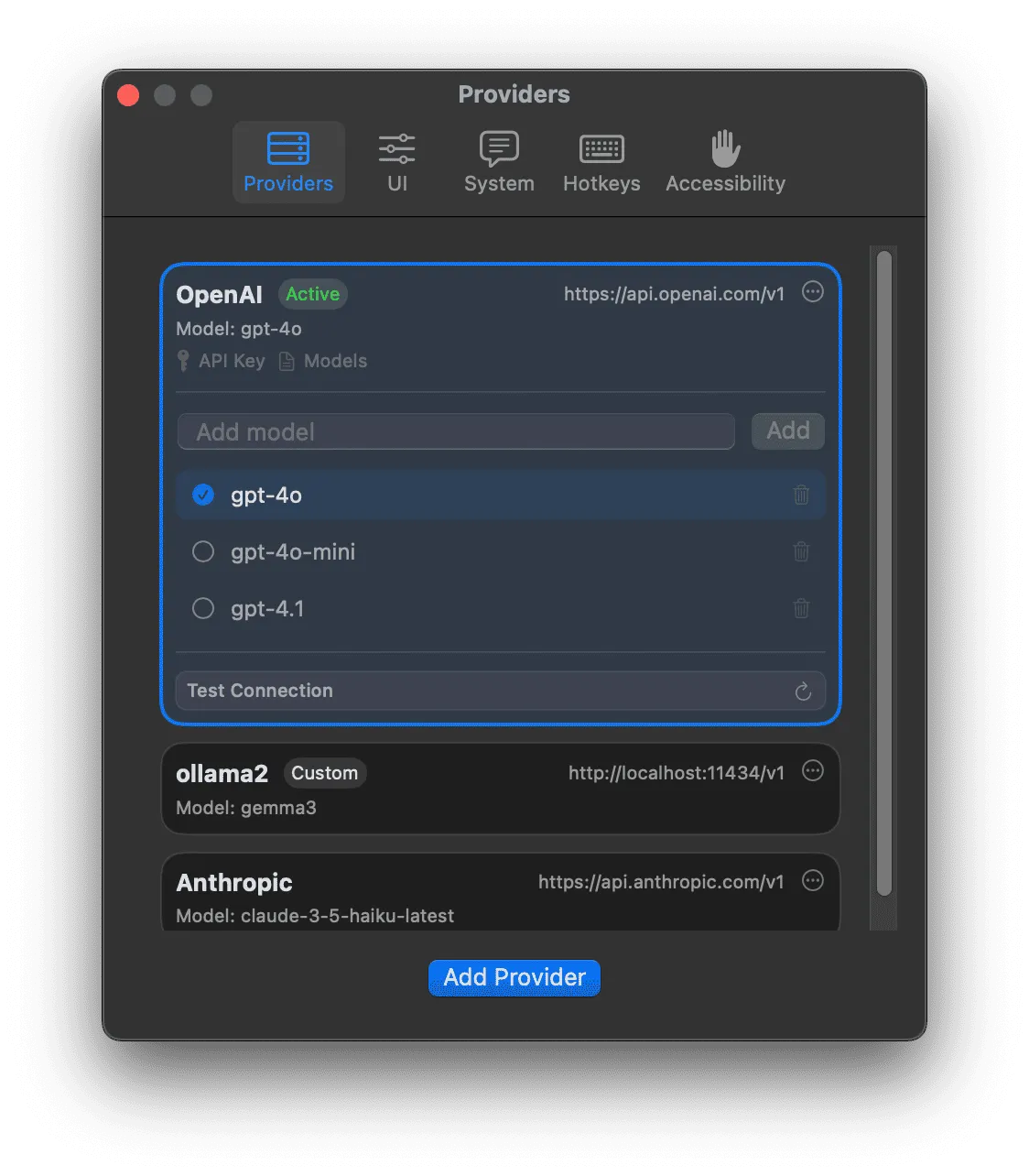
As I continued using Tomo, I found myself wanting to switch fluidly between providers and across different models within a provider.
I might use gpt-4.1 for a complex task and then switch to gpt-4o-mini to extract all the names from a long passage of text and put them in a bulleted list.
It quickly became tiresome to switch providers with the previous UI and managing the API keys outside the app was a pain. I added this provider selector UI so that multiple providers could be configured and easily switched between in the settings.
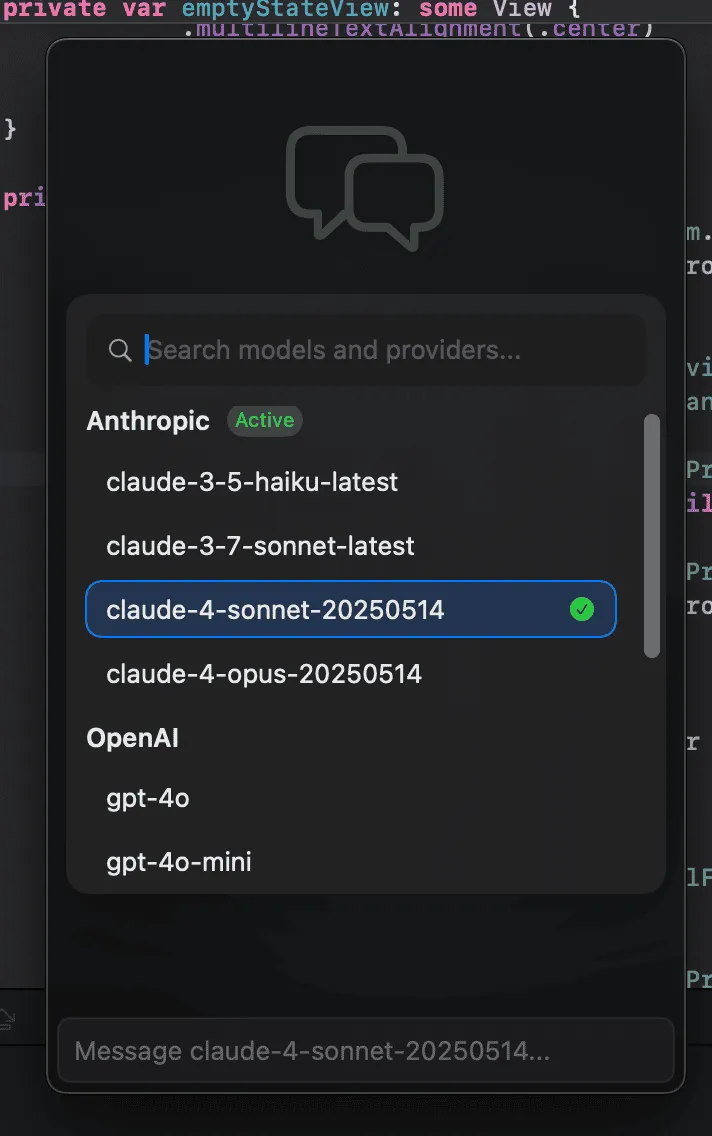
With a nice provider configuration, the next step was to make model selection as easy as possible. I added a model selector bound to the cmd+K hotkey that allowed for snappy model switching across providers. With this in place, quickly using any model from anywhere on my system became a breeze.
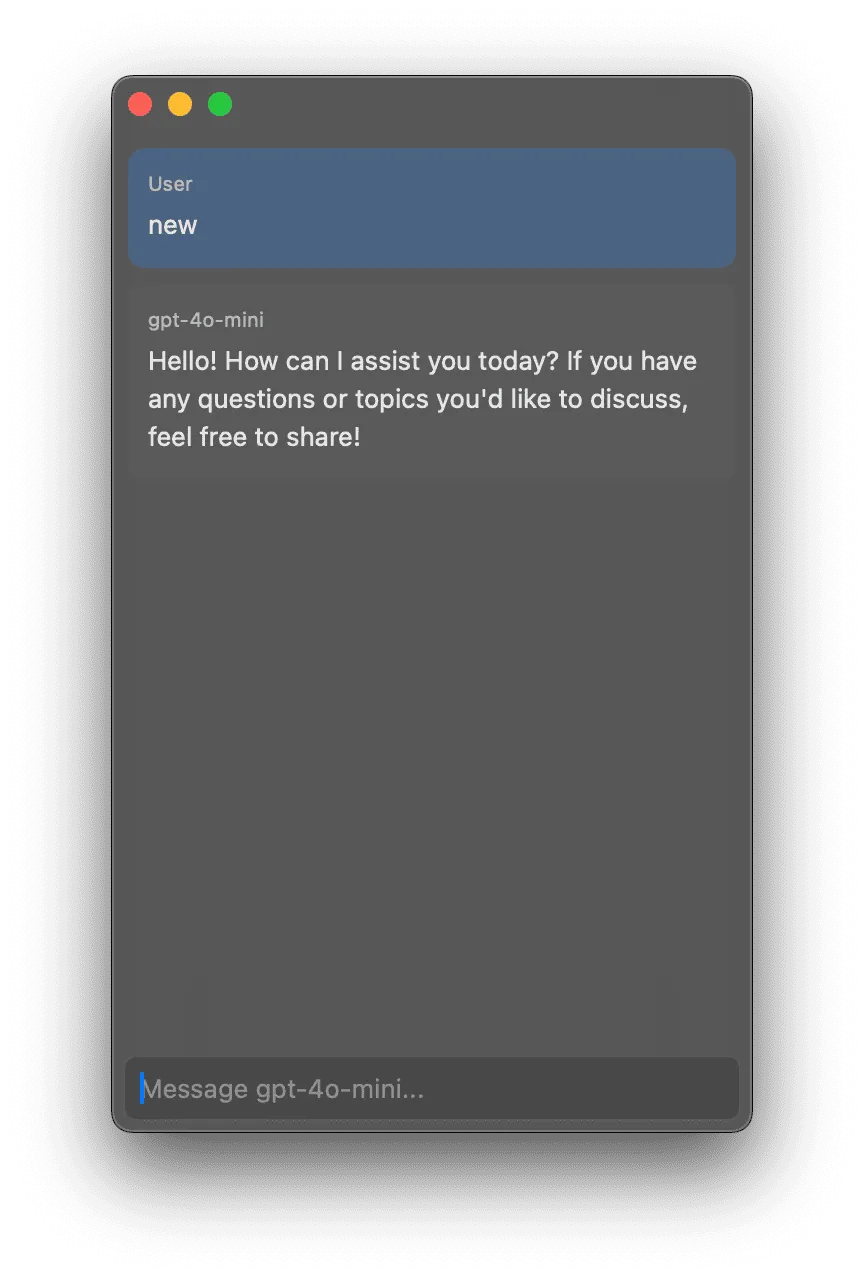
A friend graciously demoed the app and gave me a ton of feedback. One piece of this was that it was unintuitive for the app not to have the traffic light buttons by default. I typically would close the window with cmd+w and then open it again with ctrl+option+space.
I added support for these and also added a UI configuration option to hide the traffic light buttons, since that was my preferred UI. This was pretty tough to implement just right but I think it makes the app accessible to more people.
Almost two months into the project, I realized that I had never switched my operating system into light mode to see how the app would look. On this day I did that and with a little bit of polish got things looking how I wanted them.
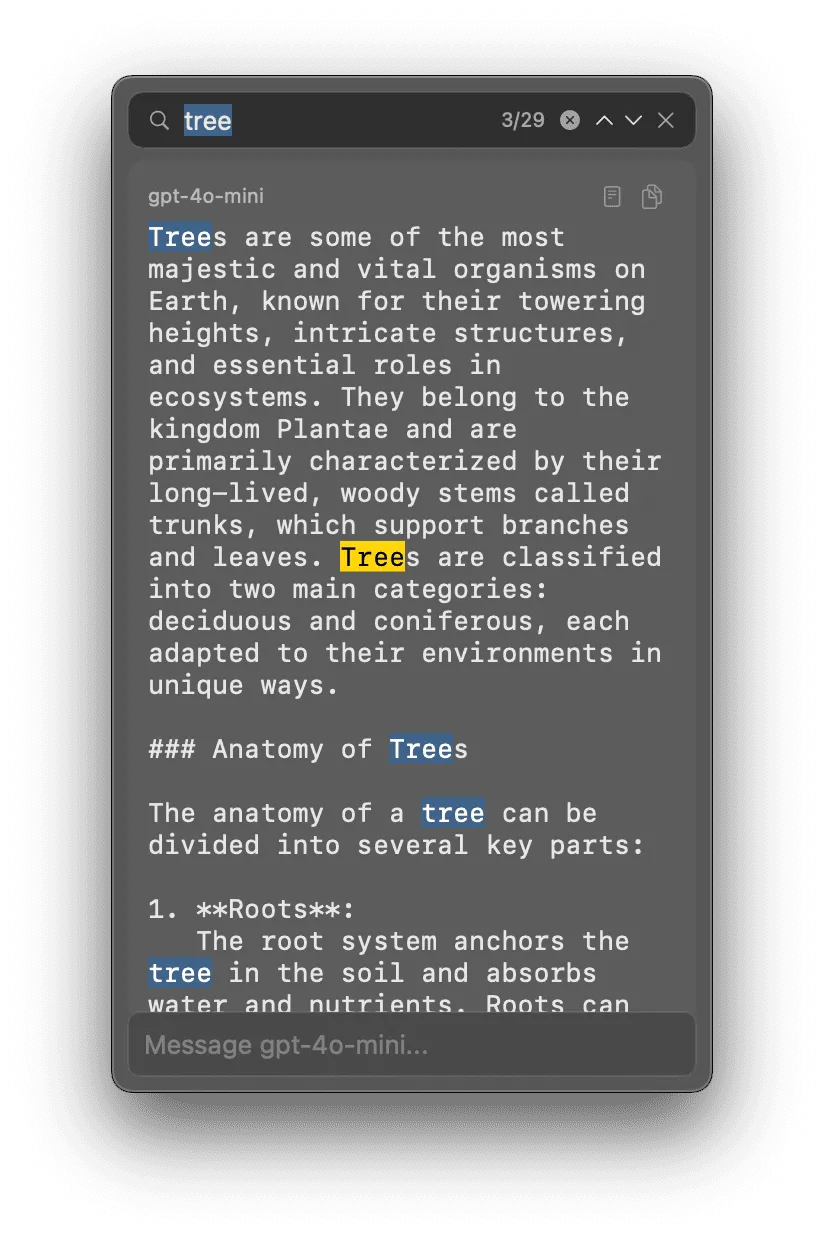
After several weeks of daily use, I found myself yearning for a cmd+f search feature. This particular feature is the main one that keeps me loyal to iTerm2.
In implementing this, I developed a true appreciation for why many terminal apps avoid implementing this feature. To complicate things further, I needed to switch from the rendered markdown to the raw markdown, since text matches occurred in the raw markdown, so that needed to be visible for match highlighting.
I also had to experiment with many different approaches for cycling through matches to ensure the highlighted match was always visible.
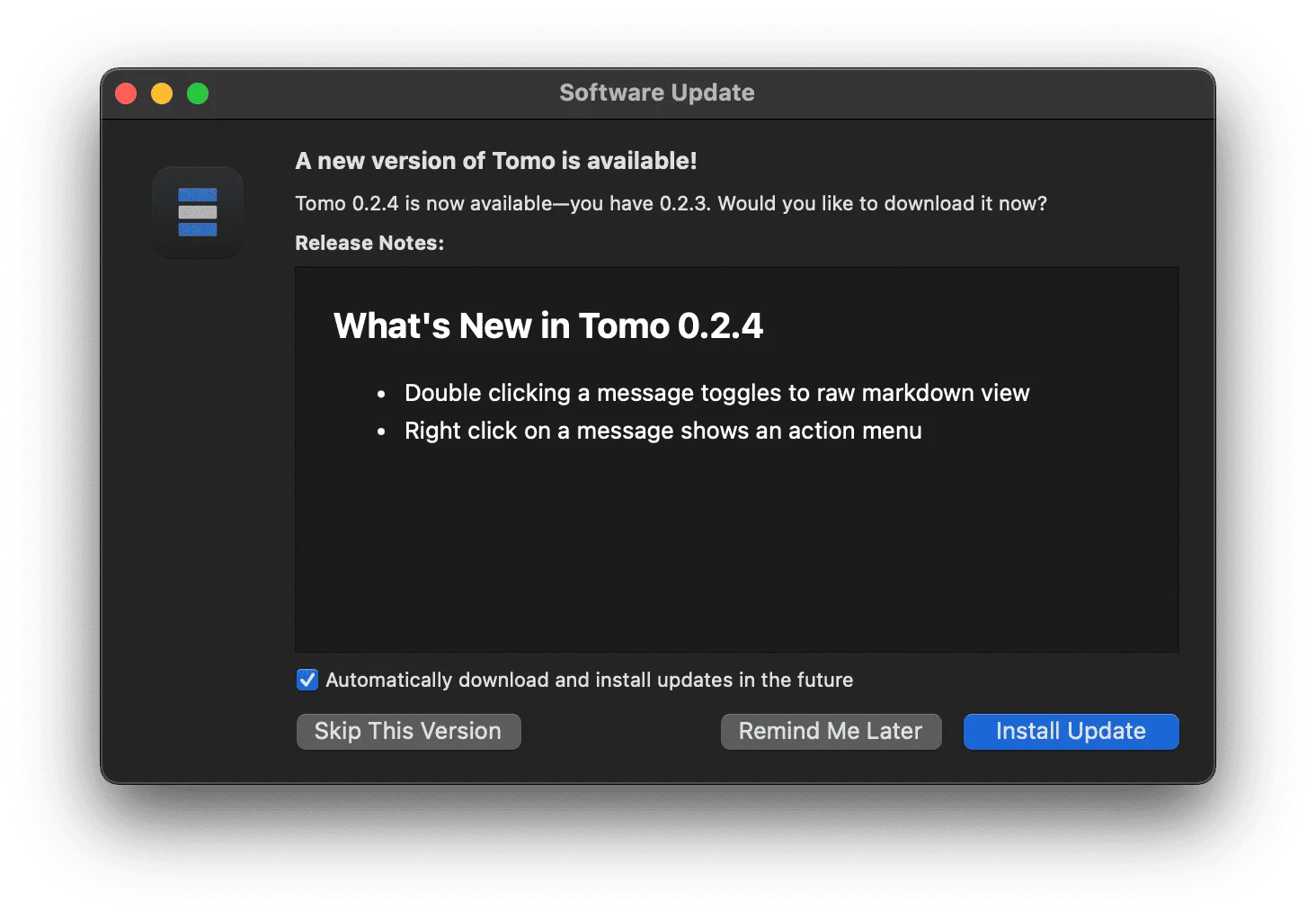
Using Tomo itself to take screenshots of Xcode and the Sparkle update framework, I was able to get updates working to easily push new versions of the app to users. At the time, I had been dragging my feet on this for a while because I had no idea how to do it, but using the language model as a pair made it an achievable afternoon project.
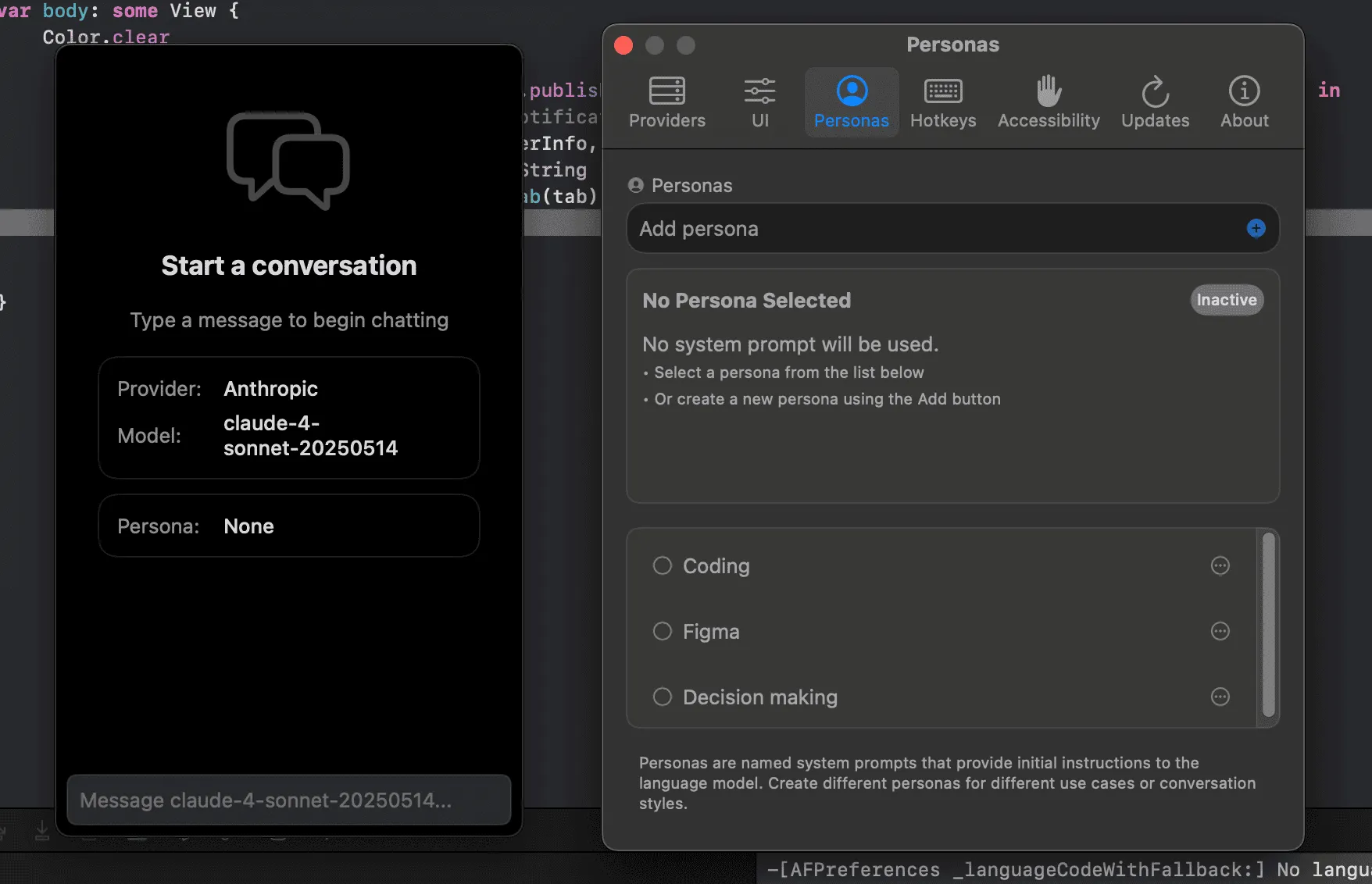
As someone aware of, but who under-uses system prompts, I resolved to bring them to Tomo as a first-class feature I called "Personas". Personas are just system prompts for a conversation. I also added selector support to make it easy to select and switch between personas.
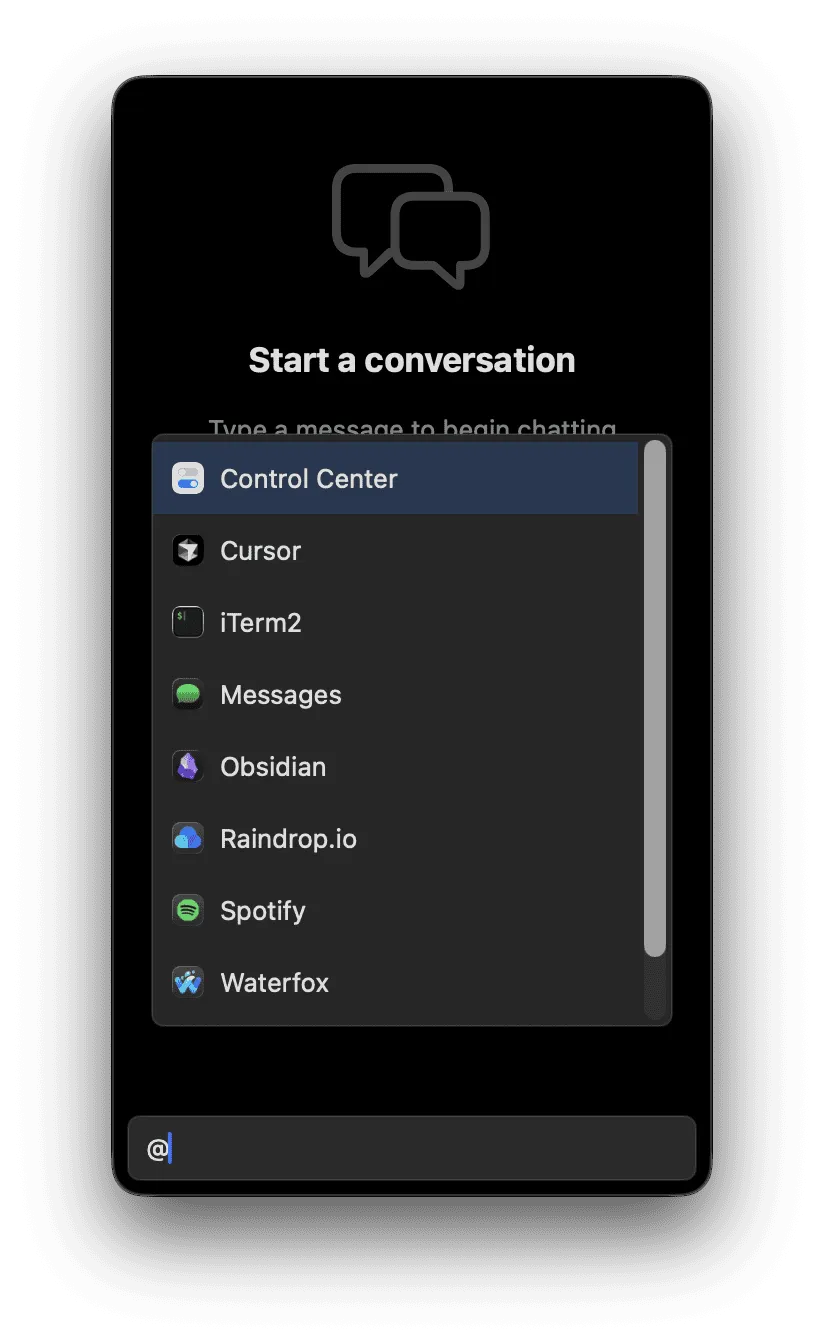
As a bonus, here's a feature I played around with but never shipped.
I found that sometimes I was working in multiple windows and wanted the LLM to take a look at what I was doing across multiple apps and help me from there.
I played around with @ referencing an app, which would automatically add screenshots of all windows to Tomo.
If I deleted the @ reference, the screenshots would be removed.
It never quite felt right so I never shipped it.